数据结构-排序(二)
数据结构-排序(二),包括 python 源代码
更新
1
219.03.13 初始
19.03.17 增加快速排序性能测试
- 参考资料
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
维基百科
算法第四版,算法导论.
导语
- 这一节包括堆排序和快速排序,及其相关证明.
- 算法导论还是有一些证明看不懂,暂时滞后了.
- 与堆排序通常提起的优先队列这里仅做简介,不再详述.
排序
- 本章约定,所涉及序列取值为正整数.
堆排序
- 堆排序的实现思路上与以前提到的排序算法有很大不同,堆排序主要是借助了–堆,这个数据结构实现了非常好的时间/空间复杂度,这里会对堆排序的复杂度进行详细证明(出自算法导论)
堆
堆(英语:Heap)是一种特别的树状数据结构,堆排序涉及的主要是二叉堆,可以看作是一个近似完全二叉树的结构,并同时满足堆积的性质.
示例
二叉堆
- 树的每一个节点对应数组的一个元素,除最底层外每层均满员,近似一颗完全二叉树,数组[0]空置.
- 第k个节点的父节点为 k\2 ,两个子节点的位置为 $2k$ 和 $2k+1$ .(通常通过宏/匿名函数定义,方便调用)
- 通过二叉堆可以很大降低相关操作的时间复杂度,具体:
- MAX-HEAPIFY: 恢复最大堆有序,时间复杂度为 $O(\lg n)$
- BUILD-MAX-HEAP: 通过无序序列,构造一个最大堆,时间复杂度为 $O(n)$
- HEAPSORT: 堆排序,时间复杂度为 $O(n\lg n)$
二叉堆有关定义
- 最大/最小堆
- 最大堆: 除根节点外,所有节点i均满足 $A[Parent(i)]\geq A[i]$.
- 最小堆: 除根节点外,所有节点i均满足 $A[Parent(i)]\leq A[i]$.
- 最大堆通常用于堆排序,最小堆用于构造优先队列.
- 高度
- 将堆看作一颗树,定义一个堆的节点高度即为该节点到叶节点最长简单路径的边的数目.
- 一个堆的高度定义为根节点的高度.
- 一个包含 n 个元素的堆的高度是 $\Theta(\lg n)$
- 证明:
数学归纳法,根据完全二叉堆的定义入手.
- 证明:
- 最大/最小堆
二叉堆有关操作
- 当一个二叉堆定义为最大/最小堆时,需要通过上浮/下沉操作使得二叉堆有序.(这里以最大堆为例)
- 上浮(swim)
- 过程
- 不符合定义的节点,与父节点交换,再与新的父节点比较,交换,直到到达根节点/找到合适位置.
- 节点的运动类似上浮.
- 时间复杂度
- 假设一颗以i为根节点、大小为n的子树,上浮恢复堆有序(MAX-HEAPIFY)的时间代价包括:
- 调整 $A[i]$ 与 $A[Parent(i)]$ 位置的时间复杂度 $\Theta(1)$
- 如果依旧不符合最大堆定义时,此时额外的代价为对子树S,运行MAX-HEAPIFY的时间代价.子树 S 以i为叶节点,大小最大为 $\frac{n}{2}$.
- 对于swim而言,子树S的最大值在 $A[i]$ 为叶节点,且原二叉堆的最下层仅有 $A[i]$ 1个叶节点取到.
- 设原二叉树高度为 h .子树S的高度为 h-1 .则
- $$\lim_{h \to +\infty} \frac{2^{h-1}-1}{2^{h-1}} = 1$$
- 因此整个过程可以用如下递归式表示
- $$T(n)\leq T(n)+\Theta(1)$$
- 因此MAX-HEAPIFY的整体时间复杂度为 $\Theta(\lg n)$
- 对一个高度为$h$的节点,MAX-HEAPIFY的整体时间复杂度为 $O(h)$
- 假设一颗以i为根节点、大小为n的子树,上浮恢复堆有序(MAX-HEAPIFY)的时间代价包括:
- 过程
- 下沉(sink)
- 过程
- 不符合定义的节点,与两子节点的较大者交换,在与新的子节点比较,直到达到叶节点/找到合适位置.
- 节点的运动类似下沉
- 时间复杂度(算法导论)
- 假设一颗以i为根节点、大小为n的二叉树,下沉恢复堆有序(MAX-HEAPIFY)的时间代价包括:
- 调整 $A[i]$ 与 $A[Left(i)]$ 与 $A[Right(i)]$ 的位置时间复杂度 $\Theta(1)$
- 如果依旧不符合最大堆定义时,此时额外的代价为对子树S,运行MAX-HEAPIFY的时间代价.子树 S 以i为根节点,大小最大为 $\frac{2n}{3}$.
- 对于sink而言,子树 S 的最大值在原二叉堆的最底层恰好半满,且 $A[i]$ 为根节点时.
- 假设原树的高度为 h ,则子树 S 的高度为 $h-1$,且子树 S 为满二叉树.子树S有 $2^{h-1}-1$个节点.
- 一颗大小为 n 的二叉树,在其最底层半满时,高度 h 满足如下关系
- $$2^{h}-1 + 2^{h-2} = n$$
反推得 - $$h=\log_2(\frac{n+1}{3})+2$$
- $$2^{h}-1 + 2^{h-2} = n$$
- 子树S与原树的规模大小比值为
- $$\lim_{h \to +\infty} \frac{2^{h-1}-1}{2^{h}-1 + 2^{h-2}}$$
代入 $h=\log_2(\frac{n+1}{3})+2$ 化简得 - $$\lim_{n \to +\infty} \frac{2n-1}{3n} = \frac2 3$$
- $$\lim_{h \to +\infty} \frac{2^{h-1}-1}{2^{h}-1 + 2^{h-2}}$$
- 因此整个过程可以用如下递归式表示
- $$T(n)\leq T(\frac{2n}{3})+\Theta(1)$$
- 因此MAX-HEAPIFY的整体时间复杂度为 $\Theta(\lg n)$
- 对一个高度为$h$的节点,MAX-HEAPIFY的整体时间复杂度为 $O(h)$
- 假设一颗以i为根节点、大小为n的二叉树,下沉恢复堆有序(MAX-HEAPIFY)的时间代价包括:
- 过程
构造二叉堆(BUILD-MAX-HEAP): 将一个数组构造为二叉堆.
- 构造(最大堆为例)
- 利用上浮(swim)
- 从后向前扫描每一个二叉堆节点,找到不符合最大堆定义的节点.
- 不符合定义的节点,与父节点交换,再与新的父节点比较,交换,直到到达根节点/找到合适位置.
- 直到扫描到根节点 $A[1]$ 为止,二叉堆有序.
- 利用下沉(sink)
- 从根节点先后扫描,找到不符合最大堆定义的节点.
- 不符合定义的节点,与两子节点的较大者交换,在与新的子节点比较,直到达到叶节点/找到合适位置.
- 扫描一半元素(叶节点可以看作大小为1的最大堆,可跳过),堆有序.
- 利用上浮(swim)
- 时间复杂度(一般使用下沉构造最大堆)
- 初步来看,下沉(sink)的时间复杂度上限是 $O(\lg n)$,BUILD-MAX-HEAP总共需要 $O(n)$次调用,一个明确的上界 $O(n \lg n)$,当还并不是将近上界,下面是更为精确的分析(从节点高度角度)
- n个元素的二叉堆高度为 $[\lg n]$,最多包含 $\frac{n}{2^{h+1}}$ 个高度为 h 的节点,
- 高度为 h 的节点运行MAX-HEAPIFY的时间复杂度为 $O(h)$.则 BUILD-MAX-HEAP 的总代价可以表示为:
- $$\sum_{h=0}^{\lg n} \frac{n}{2^{h+1}} \times O(h) = O(n \sum_{h=0}^{\lg n} \frac{h}{2^h})$$
- 对累加和求极限(等比/等差数列前n项和公式)
- $$\sum_{h=0}^{\infty} \frac{h}{2^h} = 2$$
- 则有
- $$\sum_{h=0}^{\lg n} \frac{n}{2^{h+1}} \times O(h) = O(n \sum_{h=0}^{\infty} \frac{h}{2^h}) = O(n)$$
- 我们可以得到 BUILD-MAX-HEAP 的将近上界为 $O(n)$,这意味着我们可以在线性时间内将一个无序序列构造为一个最大堆.
- 上浮构造最大堆,上浮/下沉构造最小堆证明过程类似,不加赘述.
- 构造(最大堆为例)
代码
1
2
3
4
5
6
7
8
9
10
11
12
13# sink
def sink(self, arr, i, heap_size):
largest = i
# 如果左子树较大
if 2 * i <= heap_size and arr[2 * i] > arr[i]:
largest = 2 * i
# 如果右子树较大
if 2 * i + 1 <= heap_size and arr[2 * i + 1] > arr[largest]:
largest = 2 * i + 1
# 发生交换,递归调用
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
self.sink(arr, largest, heap_size)
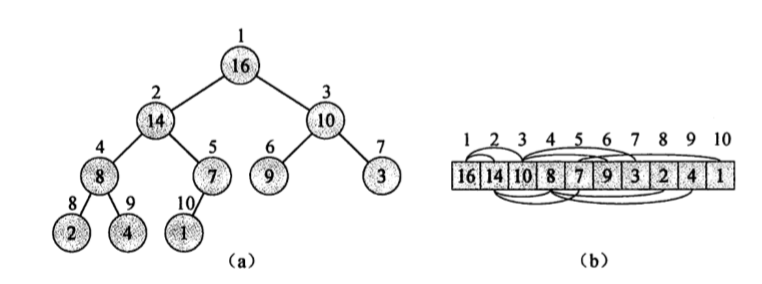
利用最大堆的堆排序
步骤
- BUILD-MAX-HEAP 将输入序列构造为最大堆.
- 取最大堆第一元素 $A[1]$ 与最大堆的最后一个元素交换位置.未排序序列长度-1.
- 对未排序序列应用 MAX-HEAPIFY 恢复堆有序.
- 不断重复 2 3,直到未排序序列长度为1,整个序列排序完成.
图解
算法复杂度
- 时间复杂度
- 第一步的 BUILD-MAX-HEAP 的时间复杂度为 $O(n)$
- 第二三步总共调用了 n-1 次 MAX-HEAPIFY,MAX-HEAPIFY的时间复杂度为 $O(\lg n)$,第二三步的总计时间复杂度为 $O(n \lg n)$
- 则堆排序的总时间复杂度为 $n \lg n$
- 空间复杂度
- 无论是 BUILD-MAX-HEAP 还是 MAX-HEAPIFY 都是原地移动,故空间复杂度为 $O(1)$.
- 时间复杂度
改进
- 先下沉再上浮
- 如果比较操作的代价比较高(字符串、key值非常长),先下沉再上浮的办法,可以减少比较次数.
- 基于这样的猜想,处于数组末尾的元素比较小的概率较大,原始的堆排序中交换至根节点后,还是会被交换到二叉堆的底部.浪费了很多比较.
- 步骤
- 将根节点交换到二叉堆的最后元素后,不再将最后的元素放到根节点位置,而是暂存到临时位置temp.
- 递归的将根节点的两个子节点中较大的子节点交换到根节点位置,相当于对空的根节点递归调用下浮(sink).
- 将暂存到temo的最后元素交换到空节点位置,对最后元素递归调用上浮(swim),恢复堆有序.
- 其他步骤相同
- 对于随机数组,这样可以将比较次数降低一半,接近归并排序,需要额外的空间,但空间复杂度仍然为 $O(1)$
- 先下沉再上浮
应用
- 堆排序是目前已知的唯一可以同时最优的利用时间和空间的排序算法,甚至在最坏的条件下时间复杂度依旧是$O(n \lg n)$,资源紧张,特别是在嵌入式设备中,只需要几行代码就可以获得良好的性能.
- 但堆排序并非没有缺点,堆排序的一个元素很少会和相邻元素比较,这样造成堆排序无法有效利用缓存,堆排序的缓存命中率相当低,不只是快速排序、归并排序,甚至低于希尔排序.
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 堆排序
def HeapSort(self, arr):
# 二叉堆的长度
heap_size = len(arr)
# 堆排序由索引1开始,插入一个元素.
arr.insert(0, 0)
# 构造最大堆
for i in range(heap_size // 2, 0, -1):
self.sink(arr, i, heap_size)
# 堆排序
while heap_size > 1:
arr[1], arr[heap_size] = arr[heap_size], arr[1]
heap_size -= 1
self.sink(arr, 1, heap_size)
# 删除插入元素
arr.pop(0)
return arr

快速排序
- 快速排序是目前应用最广的通用排序算法,基本为原地排序(或很小的辅助栈),在一般情况下比其他排序算法要快的多.
- 快速排序也是基于分治法思想实现,虽然在最糟糕情况下其时间复杂度为 $O(n^2)$,但其平均情况下时间复杂度为 $O(n \lg n)$,且 $O(n \lg n)$ 中的常数因子非常小,本节会详细进行证明(算法导论)
- 快速排序并非没有缺点,快速排序的高效非常依赖输入的序列,在实际应用中不得不非常小心的避开最糟的输入.在导致最糟情况的输入中,也指明了快速排序的改进方向,在下文中给出了几个常用的改进型(算法第四版)
原始快速排序
步骤
- 序列中选择一个基值,跳过长度为1的序列.
- 使用基值切分整个序列,将序列分为两部分,元素小于等于基值的左子列,元素大于基值的右子列.
- 对左子列,右之列递归的执行 12 ,序列排序完成.
原地切分(in-place)
- 原始版本
- 快速排序原始版本中,切分使用了一个辅助数组,切分完成后再将结果赋值会原数组.
- 这样大大降低了切分的速度,空间复杂度为$O(n)$.
- 原地切分,空间复杂度为$O(1)$.
- 选定切分元素后(一般为首尾/中间元素),将切分元素交换到待切分序列最后一个元素位置.
- 头指针start 从待切分序列的第一个元素开始,尾指针 end 由倒数第二个元素开始,与切分元素比较.
- 当头指针 start 指向元素大于切分元素,尾指针 end 指向元素小于等于切分元素时,交换头尾指针指向元素位置.
- 直到 strt 与 end 指针相遇为止,扫描结束.
- 若序列倒数第二个元素大于切分元素(end指针未动),交换两者位置.
- 这里默认采用原地切分,以下的所有内容均基于原地切分的快速排序.
- 原始版本
算法正确性证明(分治法证明)
图解
算法复杂度
- 时间复杂度: 由快速排序的步骤直观上可以知道,快速排序的性能非常依赖切分的方式和切分元素的选择.
- 最坏情况切分
- 使用代入法进行分析.
- 假设 $T(n)$ 时最坏情况下 quicksort 在输入规模为 n 上花费的时间代价.则有递归式 ($\Theta(n)$为切分操作的比较代价)
- $$T(n) = max_{0\leq q \leq n-1}(T(q)+T(n-q-1)) + \Theta(n)$$
切分操作的两个子问题的规模为 n-1 ,所以参数 q 的取值范围为 $[0\leq q \leq n-1]$.
- $$T(n) = max_{0\leq q \leq n-1}(T(q)+T(n-q-1)) + \Theta(n)$$
- 假设 $T(n) \leq cn^2$ ,c为常数.带回原递归方程得
- $$T(n) \leq max_{0\leq q \leq n-1}(cq^2 + c(n-q-1)^2) + \Theta(n) = c \times (q^2 + (n-q-1)^2) + \Theta(n)$$
方程 $q^2 + (n-q-1)^2$ ,在 $q = 0$ 或 $q=n-1$ 两个端点值时,取到最大值.因此二元一次方程得二阶导数为正,开口向上,其最大值为 $max_{0\leq q \leq n-1}(cq^2 + c(n-q-1)^2) \leq (n-1)^2 = n^2 -2n + 1$.带回原方程得. - $$T(n) \leq cn^2 - c(2n-1) + \Theta(n) \leq cn^2$$
如上方程所示,这里选择一个足够大得常数c,使得 $c(2n-1) > \Theta(n)$,因此得到 $T(n) = O(n^2)$
- $$T(n) \leq max_{0\leq q \leq n-1}(cq^2 + c(n-q-1)^2) + \Theta(n) = c \times (q^2 + (n-q-1)^2) + \Theta(n)$$
- 因此可以得到以下结论
- 当切分产生的两个子问题分别包含 n-1 和 0 个元素时,快速排序的最坏情况发生.
- 最坏情况下快速排序得时间复杂度为 $O(n^2)$
- 另外一个有趣的特点是,当切分元素选择首尾元素时,无论输入序列是逆序/有序,都是最坏情况,时间复杂度都是 $O(n^2)$,而插入排序在输入为正序时,时间复杂度为 $O(n)$
- 最好情况切分
- 可能得最好情况切分是,切分操作得到得两个子序列规模都不到与 $\frac n2$,(切分后一个为 $\frac n2$,另一个为 $\frac n2 - 1$),此时运行时间得递归式为
- $$T(n) = 2T(\frac n2) + \Theta(n)$$
- 由master定理得,时间复杂度为 $\Theta(n \lg n)$
- 平衡切分
- 快速排序的切分情况并非是最好情况,这里假定切分后,子问题的规模比值为 $9:1$.这里时间代价的递归式为
- $$T(n) = T(\frac{9n}{10}) + T(\frac{n}{10}) + cn$$
- 这里将最好情况切分的 $\Theta(n)$ 显式写为了 $cn$.
![sort]()
如上图所示,树的每一层的代价都是 $cn$,直到深度为 $\log_{10} n = \Theta(\lg n)$时为止,之后每一层的代价都小于 $cn$,直到深度为 $\log_{\frac{10}{9}}n = \Theta(\lg n)$ 终止.因此整个的时间复杂度为 $O(n \lg n)$- 这里的结论可能有些反直觉,即: 在常数比例切分情况下,无论比例取值如何,时间复杂度都为 $O(n \lg n)$.
- 平均情况
- 这里我们假定所有输入元素各异.
- 平均情况下,指输入序列的所有排序都是等概率的,相应的选取切分元素的概率也是相等的.
- 简略形式化分析
- 假定好的切分(最好情况)和差的切分(最坏情况)间隔出现.
- 假设根节点处为最坏切分,产生规模为 $n-1$ 和 0 的两个子序列.
- 之后为最好切分,产生规模为 $\frac{n-1}{2}-1$ 和 $\frac{n-1}{2}$ 的两个子序列.
- 到这一步分析时间的复杂度,假设大小为 0 的子序列的时间代价为 1 ,好坏交替的切分,共产生了规模为 0 、 $\frac{n-1}{2}-1$ 和 $\frac{n-1}{2}$ 的3个子序列,这一组合的切分代价为 $\Theta(n) + \Theta(n-1) = \Theta(n)$,差的切分代价被好的切分所平均.
- 总体上来看,好坏间隔出现的情况下,总体的时间复杂度依旧为 $O(n \lg n)$,只不过其常数因子要比最好情况切分要大.
- 详细证明
- 需要储备 概率论,调和级数..略..(知识储备未到)
- 平均情况下时间复杂度依旧为 $n \lg n$
- 最坏情况切分
- 空间复杂度
- 对于使用原地排序的快速排序而言,不涉及辅助空间,空间消耗为递归栈.
- 最好情况下需要 $O(\lg n)$ 次调用,空间复杂度为 $O(\lg n)$
- 最坏情况下需要 $O(n)$ 次调用,空间复杂度为 $O(n)$
- 时间复杂度: 由快速排序的步骤直观上可以知道,快速排序的性能非常依赖切分的方式和切分元素的选择.
改进
- 在小规模序列时,使用插入排序,与归并/希尔排序的改进思路相同.
- 快速排序非常依赖切分的平衡,如果切分不当,快速排序可能退化到 $O(n^2)$ .对于数据量非常大的情况下,为避免最坏情况,我们引入随机化,具体有两种:
- 对整个输入的序列随机化,然后再进行快速排序.
- 选择切分元素时,引入随机化抽样,效果相同.
- 还有一种对切分元素选择的改进: 选取切分元素时,随机选择3个元素,选择中位数作为切分元素.
- 虽然我们讨论快速排序的时间复杂度时假定输入元素随机,但现实的数据并非如此,针对大量重复数据的输入序列,稍加改进,即可将排序的时间复杂度由对数级别降低到线性级别.
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51def QuickSort(self, arr):
lens = len(arr) - 1
# 抽样
def simplerandom(arr, start, end):
return (start + end) // 2
# 随机抽样
def simplerandom(arr, start, end):
return random.randint(start, end)
# 三抽样
def three(arr, start, end):
mid = (start + end) // 2
a = arr[start] < arr[mid]
b = arr[mid] < arr[end]
c = arr[start] < arr[end]
if a and b:
i = mid
elif c and (not b):
i = end
elif c and (not a):
i = start
elif b and (not c):
i = end
elif a and (not c):
i = start
else:
i = mid
return i
def partition(arr, start, end, i):
# 交换切分元素到最后
arr[i], arr[end] = arr[end], arr[i]
i = start - 1
for j in range(start, end):
# 一次交换一个元素到确定位置
if arr[j] < arr[end]:
i += 1
arr[i], arr[j] = arr[j], arr[i]
# 防止最坏情况发生
arr[i + 1], arr[end] = arr[end], arr[i + 1]
return i + 1
def sort(arr, start, end):
if start >= end:
return
# 选取切分元素
i = simplerandom(arr, start, end)
# 中间位置
p = partition(arr, start, end, i)
sort(arr, start, p - 1)
sort(arr, p + 1, end)
sort(arr, 0, lens)
return arr


3向快速排序
三向切分快速排序.
- 切分的操作将数组切分为3部分: 小于切分元素,等于切分元素,大于切分元素.
- 相比原始版本,在大量重复元素时,跳过了大量重复元素交换,切分的子问题小的多.
- 算法复杂度的证明需要概率和级数相关知识…😟
- 存在大量重复数据的序列排序,时间复杂度为 $O(n)$
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39# 切分3
def partition_3(self, arr, start, end, i):
arr[i], arr[start] = arr[start], arr[i]
left, right, i = start, end, start + 1
# 切分元素
partition = arr[start]
while i <= right:
cmp = arr[i] - partition
# 小于切分元素
if cmp < 0:
arr[i], arr[left] = arr[left], arr[i]
left, i = left + 1, i + 1
# 大于切分元素
elif cmp > 0:
arr[i], arr[right] = arr[right], arr[i]
right -= 1
# 等于切分元素
else:
i += 1
return (left, right)
# 3向切分
def sort3(self, arr, start, end, choose, partition3):
if start >= end:
return
# 选取切分元素
i = choose(arr, start, end)
# 中间位置
p = partition3(arr, start, end, i)
self.sort3(arr, start, p[0] - 1, choose, partition3)
self.sort3(arr, p[1] + 1, end, choose, partition3)
# 取固定值
def choose_simple(self, arr, start, end):
return (start + end) // 2
def sort3_simple(self, arr):
lens = len(arr) - 1
self.sort3(arr, 0, lens, self.choose_simple, self.partition_3)
return arr
性能测试
python默认的递归调用深度为 999 ,大量数据测试时,对于递归实现的排序算法实在不够用,需要修改到一个较大数值.
1
2
3import sys
sys.setrecursionlimit(100000) # 这里设置为十万
简略
通过python的装饰器来输出函数运行时间,这里有个bug是,函数会重复执行两遍…
代码
1
2
3
4
5
6
7
8
9
10
11import functools
def exeTime(func):
def newFunc(*args, **args2):
start = time.time()
func(*args, **args2)
end = time.time()
print('{%s} exec %f' % (func.__name__, end - start))
return func(*args, **args2)
return newFunc
结果
随机生成 10000 个int类型数据.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18{selectionsort} exec 5.326228
{InsertSort} exec 6.251139
{ShellSort} exec 0.059285
{BubbleSort} exec 12.126901
{MergeSort} exec 0.100686
{QuickSort} exec 0.109973
{QuickSort_random} exec 0.178610
{QuickSort_three} exec 0.121637
{HeapSort} exec 0.257240结果简单看以下就好,为了方便,快速排序这里用的递归写法,实际测试需要非递归,且因为数据是随机生成,不同排序算法的适用范围也不尽相同.
快速排序性能测试
简略的性能测试实在感觉有问题,重新整理了快速排序的代码,进行完整测试.
- 普通快速排序的切分操作分为了 partition_a 和 partition_b.两者实现/效果完全相同.这里仅为测试两种实现的性能.
- 选择切分元素分为了 simple(第一个元素), random(随机选择),three(取头尾中间3个元素的中位数)
- 小规模数组(<=5),可选 改为插入排序.
代码
- 代码冗余较多,仅供参考.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237class quicksort(object):
# 快速排序a
def simple_a(self, arr):
lens = len(arr) - 1
self.sort(arr, 0, lens, self.choose_simple, self.partition_a)
return arr
# 快速排序a_inser
def simple_a_inser(self, arr):
lens = len(arr) - 1
self.sort_inser(arr, 0, lens, self.choose_simple, self.partition_a)
return arr
# 快速排序b
def simple_b(self, arr):
lens = len(arr) - 1
self.sort(arr, 0, lens, self.choose_simple, self.partition_b)
return arr
# 快速排序b
def simple_b_inser(self, arr):
lens = len(arr) - 1
self.sort_inser(arr, 0, lens, self.choose_simple, self.partition_b)
return arr
def random_a(self, arr):
lens = len(arr) - 1
self.sort(arr, 0, lens, self.choose_random, self.partition_a)
return arr
# 快速排序b
def random_b(self, arr):
lens = len(arr) - 1
self.sort(arr, 0, lens, self.choose_random, self.partition_b)
return arr
def three_a(self, arr):
lens = len(arr) - 1
self.sort(arr, 0, lens, self.choose_three, self.partition_a)
return arr
def three_a_inser(self, arr):
lens = len(arr) - 1
self.sort_inser(arr, 0, lens, self.choose_three, self.partition_a)
return arr
# 快速排序b
def three_b(self, arr):
lens = len(arr) - 1
self.sort(arr, 0, lens, self.choose_three, self.partition_b)
return arr
# 快速排序b
def three_b_inser(self, arr):
lens = len(arr) - 1
self.sort_inser(arr, 0, lens, self.choose_three, self.partition_b)
return arr
def sort3_simple(self, arr):
lens = len(arr) - 1
self.sort3(arr, 0, lens, self.choose_simple, self.partition_3)
return arr
def sort3_simple_inser(self, arr):
lens = len(arr) - 1
self.sort3_inser(arr, 0, lens, self.choose_simple, self.partition_3)
return arr
def sort3_random(self, arr):
lens = len(arr) - 1
self.sort3(arr, 0, lens, self.choose_random, self.partition_3)
return arr
def sort3_three(self, arr):
lens = len(arr) - 1
self.sort3(arr, 0, lens, self.choose_three, self.partition_3)
return arr
def sort3_three_inser(self, arr):
lens = len(arr) - 1
self.sort3_inser(arr, 0, lens, self.choose_three, self.partition_3)
return arr
# 取固定值
def choose_simple(self, arr, start, end):
return (start + end) // 2
# 随机抽样
def choose_random(self, arr, start, end):
return random.randint(start, end)
# 三抽样
def choose_three(self, arr, start, end):
mid = (start + end) // 2
a = arr[start] < arr[mid]
b = arr[mid] < arr[end]
c = arr[start] < arr[end]
if a and b:
i = mid
elif c and (not b):
i = end
elif c and (not a):
i = start
elif b and (not c):
i = end
elif a and (not c):
i = start
else:
i = mid
return i
# 切分普通
def partition_a(self, arr, start, end, i):
# 交换切分元素到最后
arr[i], arr[end] = arr[end], arr[i]
i = start - 1
for j in range(start, end):
# 一次交换一个元素到确定位置
if arr[j] < arr[end]:
i += 1
arr[i], arr[j] = arr[j], arr[i]
# 防止最坏情况发生
arr[i + 1], arr[end] = arr[end], arr[i + 1]
return i + 1
# 切分
def partition_b(self, arr, start, end, i):
# 交换切分元素到最后
arr[i], arr[end] = arr[end], arr[i]
left, right, partition = start, end - 1, arr[end]
while left < right:
# 选取左边需要交换的元素
while left < right and arr[left] < partition:
left += 1
# 选取右边需要交换的元素
while left < right and arr[right] >= partition:
right -= 1
# 交换
arr[left], arr[right] = arr[right], arr[left]
# 如果右指针未动
if arr[right] < arr[end]:
right += 1
else:
arr[right], arr[end] = arr[end], arr[right]
return right
# 切分3
def partition_3(self, arr, start, end, i):
arr[i], arr[start] = arr[start], arr[i]
left, right, i = start, end, start + 1
# 切分元素
partition = arr[start]
while i <= right:
cmp = arr[i] - partition
# 小于切分元素
if cmp < 0:
arr[i], arr[left] = arr[left], arr[i]
left, i = left + 1, i + 1
# 大于切分元素
elif cmp > 0:
arr[i], arr[right] = arr[right], arr[i]
right -= 1
# 等于切分元素
else:
i += 1
return (left, right)
def sort(self, arr, start, end, choose, partition):
if start >= end:
return
# 选取切分元素
i = choose(arr, start, end)
# 中间位置
p = partition(arr, start, end, i)
self.sort(arr, start, p - 1, choose, partition)
self.sort(arr, p + 1, end, choose, partition)
def sort_inser(self, arr, start, end, choose, partition):
if (start + 5) >= end:
self.InsertSort(arr, start, end)
return
# 选取切分元素
i = choose(arr, start, end)
# 中间位置
p = partition(arr, start, end, i)
self.sort_inser(arr, start, p - 1, choose, partition)
self.sort_inser(arr, p + 1, end, choose, partition)
# 3向切分
def sort3(self, arr, start, end, choose, partition3):
if start >= end:
return
# 选取切分元素
i = choose(arr, start, end)
# 中间位置
p = partition3(arr, start, end, i)
self.sort3(arr, start, p[0] - 1, choose, partition3)
self.sort3(arr, p[1] + 1, end, choose, partition3)
# 3向切分
def sort3_inser(self, arr, start, end, choose, partition3):
if (start + 5) >= end:
self.InsertSort(arr, start, end)
return
# 选取切分元素
i = choose(arr, start, end)
# 中间位置
p = partition3(arr, start, end, i)
self.sort3_inser(arr, start, p[0] - 1, choose, partition3)
self.sort3_inser(arr, p[1] + 1, end, choose, partition3)
def InsertSort(self, arr, start, end):
for i in range(start, end + 1):
temp = arr[i]
j = i - 1
# 由后向前扫描
while j >= 0 and temp < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = temp
return arr测试: 测试依旧是通过装饰器来输出函数运行时间.
大量随机元素,
代码
1
2
3
4
5
6
7
8
9
10
11
12
13arr = randoms.list_int(n=100000, w=1000000)
sys.setrecursionlimit(100000) # 例如这里设置为十万
arr = randoms.list_int(n=100000, w=100000) # 10万个随机数,取值范围在10万以内正整数
quicksort = quicksort()
q = quicksort.simple_a(arr.copy())
q = quicksort.simple_b(arr.copy())
q = quicksort.random_a(arr.copy())
q = quicksort.random_b(arr.copy())
q = quicksort.three_a(arr.copy())
q = quicksort.three_b(arr.copy())
q = quicksort.sort3_simple(arr.copy())
q = quicksort.sort3_random(arr.copy())
q = quicksort.sort3_three(arr.copy())结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15{simple_a} exec 0.968822
{three_a_inser} exec 0.696849
{simple_b} exec 0.997970
{simple_b_inser} exec 0.806271
{random_a} exec 1.404220
{random_b} exec 1.387455
{three_a} exec 0.773145
{three_a_inser} exec 0.623866
{three_b} exec 0.808415
{three_b_inser} exec 0.608619
{sort3_simple} exec 1.129342
{sort3_simple_inser} exec 0.925134
{sort3_random} exec 1.581109
{sort3_three} exec 1.016478
{sort3_three_inser} exec 0.801868分析
- 两种切分的实现方式,效果太差不多,切分元素选择相同时,各有快慢.
- 随机数组,小规模数组改为插入排序确实可以加快排序,运行时间差不多可以降低 20%~30%.
- 切分元素使用 3取样中位数最快.运行时间降低可以降低 10%~15%.
- 此处随机选取切分元素运行时间最长原因
- 输入的测试序列,已经是随机生成的随机数组了,固定选择一个位置作为切分元素,已经相当于输入实际数组 random 选择.
- 这里在输入随机数组情况下,又进行随机选择,浪费了时间.
- 3向切分的优势在随机数组中并不明显.
- 对随机数组最快的是 切分元素-3取样中位数 + 小规模数组改为插入排序.
重复数组
代码相同,只是将元素的取值范围限制在1000以内,数组规模限制在5万(10万一直提示段错误..)
结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15{simple_a} exec 1.643641
{three_a_inser} exec 1.935780
{simple_b} exec 2.162134
{simple_b_inser} exec 2.283103
{random_a} exec 1.953468
{random_b} exec 2.484580
{three_a} exec 1.669534
{three_a_inser} exec 1.794587
{three_b} exec 2.267951
{three_b_inser} exec 2.420400
{sort3_simple} exec 0.138570
{sort3_simple_inser} exec 0.138882
{sort3_random} exec 0.160800
{sort3_three} exec 0.100529
{sort3_three_inser} exec 0.100937分析
- 大量重复元素的数组,3向切分的消耗时间,直接下降了一个数量级.
- 小规模数组改为插入排序 效果不佳与这里插入排序的实现有关,大量重复的子数组,其实无需进行插入排序.
- 对大量重复元素的数组,3向切分+3取样中位数 是最快的组合.
结语
- 排序结束,下一篇为查找.分为两篇,头一篇为二叉树查找(二叉树查找,平衡查找树,红黑树等)
相关文章