数据结构-图(一)图基础,可视化
数据结构-图(一)图基础-数据结构/可视化等
源码: https://github.com/Jasper-1024/python/tree/master/data_structure/Graph
更新
1
219.05.14 初始
19.05.31 恢复更新,添加保存/可视化等
- 参考资料
https://algs4.cs.princeton.edu
https://graphviz.readthedocs.io/en/stable/examples.html
算法第四版,算法导论.
导语
还是在泥潭里,心灰意冷.暂时放弃(5.31)…开始断断续续写了一些图的内容,这里是图的基础内容.- 以算法第四版为主,算法导论为辅.
- 代码在这里 https://github.com/Jasper-1024/python/tree/master/data_structure/Graph
图
图论是数学的一个相当重要的分支,在现代电子计算机出现后,对图的算法相对开始刚刚不久,但相对的图的算法在现代生活的应用却非常广泛.
最简单的电子地图的寻找路径,PCB的布局,搜索引擎编制的超链接巨网,任务调度等等.
在这一节,对图的定义和API约束均以算法第四版为主.
边: 两个顶点之间的连接,而图的区分主要依据就边的类型.
图
- 无向图: 边没有方向
- 有向图: 边有方向的
- 加权图: 边带有权值
- 有向加权图: 边有方向并且带有权值
本节以无向/有向图说明.
无向图
在这里我们有两种特殊情况: 自环 和 平行边,但在实际中除非说明,否则默认不存在自环/平行边.
无向图即边没有方向的简单图.
连通图: 如果从任意一个定点都存在一条路径链接另一个顶点,则称这幅图为连通图.
无环图: 一个不包含环的图,寻找一定条件的无环图是图的算法的重要部分.
树/森林: 数是一幅无环连通图,而森林是互不相连的树的集合.
- 示例:
![1]()
- 示例:
其他有关术语
- 度数: 即一幅在这个顶点边的数目.
- 路径/环的长度: 即这条通路上边的数目
- 图的密度: 已链接的顶点对占所有可能被连接的顶点对的比例.


有向图
有向图中边是单向的,每条边连接的两个顶点都是一个有序对.邻接性是单向的.
有向图的大部分定义与无向图相同,仅个别定义因边的方向性而有改变.
入度: 指向这个顶点的边的数目
出度: 由这个顶点指出的边的数目.
与无向图类似,除非特别标明,无平行边和自环.

数据结构
为了方便这里我们将算法上定义的图的基础API合并.增加保存/加载(5.31)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38# 图的基类
class GH(object):
# v 个顶点的图
def __init__(self, v):
pass
# 顶点数
def rV(self):
pass
# 边数
def rE(self):
pass
# 添加边 v-m
def addEdge(self, v, e):
pass
# 返回v相邻的所有顶点
def adjlist(self, v):
pass
# 反向图 (有向图)
def reverse(self):
pass
# 字符串
def toString(self):
pass
# save to file
def save(self):
pass
# load from file
def load(self, file):
pass数据结构
- 示例
- 邻接表
- 一个以顶点为索引的列表数组,其中每个元素是和该顶点相邻的所有顶点.
![5]()
- 邻接矩阵
- 一个N*N的矩阵,当顶点 v 与 w 存在边时,将第 v 行 w 列的元素置为 true.
![6]()
- 示例
优缺点
邻接表
- 使用的空间和 V+E(顶点个数和边的数量正比)
- 添加一条边时间复杂度为常数.
- 遍历顶点 V 的所有相邻顶点与 V 的度数成正比.
- 允许自环和平行边
- 表示边的权重时需要小改一下边的数据结构.
邻接矩阵
- 使用空间与 成正比
- 添加一条边时间复杂度为常数.
- 判断两个顶点是否相连的时间复杂度为常数.
- 只允许一次自环,不允许平行边
- 表示边权重时,直接写入对应数值,不需要修改数据结构.
选择
- 一般的稀疏图 () 时,选择邻接表,稠密图 () 选择邻接矩阵.
- 快速判断两个顶点是否相连,选择邻接矩阵.
- 当 远远大于现有计算机内存时,选择邻接表.
我们在 GH 模块中实现了有/无向图的邻接表和邻接矩阵.
代码路径
https://github.com/Jasper-1024/python/tree/master/data_structure/Graph/GH
算法中的前提
- 非声明情况下,无自环和平行边.
- 所有顶点由 0 开始到 N 结束,数字 N 代表共 N+1 个顶点.
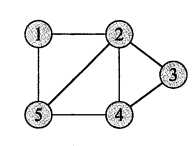


可视化
可视化还是使用 Graphviz
官方的例子
https://graphviz.readthedocs.io/en/stable/examples.html
这里配合 API def adjlist(self, v),实现.
代码路径
https://github.com/Jasper-1024/python/blob/master/libs/prgraph.py
有/无向图
(5.31 )Graphviz 一旦添加一个带颜色的边,就是另外一个平行边了,这里使用节点颜色变化代替边的颜色变化.
![4235.35302734375.png]()

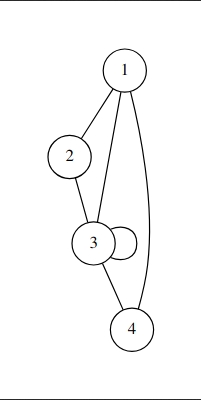
保存到文件
算法中实现是按一定规则写入 .txt 文件,但这里不在那么麻烦.
这里使用 python 的 pickle 模块,可以非常简单的保存对象.
示例
1
2
3
4
5
6
7
8
9def save(self, fileName: str = 'Graph.pickle'):
file = open(fileName, 'wb')
pickle.dump(self, file)
file.close
def load(self, fileName: str = 'Graph.pickle'):
with open(fileName, 'rb') as file:
graph = pickle.load(file)
return graph
结语
- 接下来应该会调整一下写 blog 的节奏,增加频率,减少一点篇幅,确保一个萝卜一个坑.
- 下一篇是 图的遍历,深度/广度/联通性问题.