SWIFT - Predictive Fast Reroute -翻译
SWIFT 文章翻译
资料来源:
https://vanbever.eu/pdfs/vanbever_swift_sigcomm_2017.pdf
更新
1
20.10.29 初稿完成
导语
SWIFT 文章翻译,结果被告知不需要研究这么细…😓…
介绍
官方网站
Github
网络运营商面临这各种网络故障,每次都造成了大量网络中断时间,一次网络中断导致高昂的损失.
问题在于 BGP 收敛太慢.
- 全球范围内经层发生大规模的 bgp 撤回突发事件
- bgp 慢速收敛可能导致数十秒的数据平面停机
这里提出了 SWIFT 可以在几秒钟内恢复路由链接.
- swift 引入了预测算法,可以根据很少的控制层面 bgp 消息,快速预测故障,代价是一定的准确性.
- 另一个是引入了新的数据平面编码,可以快速灵活的更新受影响的转发条目.
swift 可以部署在现有设备,无需更改 bgp.
目前针对真实的 bgp 轨迹,swift 可以短时间内预测故障,准确率 90%,恢复 99% 的受影响路由.
2 bgp 收敛缓慢
在这一节,我们证明了 bgp 收敛缓慢和远程断路是相关的.
2.1 节讨论了 bgp 收敛缓慢的原有,以及在受控条件下 bgp 收敛缓慢对数据平面的影响.
2.2 节提供了实际的 BGP 跟踪数据,和来自运营商的反馈,证明了因特网的 bgp 收敛缓慢问题会导致即使是热门目的地,也会造成严重的交通损失(??大意是 bgp 收敛缓慢,导致的后果很严重)
2.1 bgp 收敛缓慢会导致大量数据平面丢失

图 1(a) 描述了一个 bgp 收敛缓慢的示例.每一个 AS i 都起源于一个不同的前缀集合,我们专注在 的共 21k 前缀,在 (5,6) 链接故障的前后,与互联网现状相反,我们假设所有 AS 都部署了快速重路由,这个技术允许在有备份路径的情况下,故障后快速恢复连接.
1(a) 和 1(b) 显示了故障前后 AS 路由的情况. AS 5 在故障前,知道一条经过 AS3 到 的备份路径,但是因为域间策略(例如 partial transit),AS5 并不知道 和 的备份路径: 对于这些前缀,链路失效后,AS 5 通过 AS2 才恢复连接..for those prefixes, AS 5 recovers connectivity after the failure via AS 2.
(5,6) 故障后,AS5 立刻恢复了 的连接,将路径切换到了备用路径(通过 AS3).因为 AS5 没有 和 的备份路径,对于(10+1k)前缀,创建了一个路由黑洞.
在控制层面,故障导致 AS5 发送了 10k 路径更新,以通知它现在使用新的路径到 ,以及随着 (10+1k) 路径撤销,通告路径 (5,6,8) 不通.
2.1.1 bgp 信息隐藏会降低收敛速度
对于 AS1 和 AS2 来说,(5,6) 断路是远程故障,伴随着到 和 流量的损失.本质上来说收敛缓慢,因为 AS1 和 AS2 只有它们邻居的最佳路径信息,而不是全局的所有可用路径.
发生故障时,AS1 AS2 被迫等待大量路径更新和撤销的通告,一次只能到达一个前缀.bgp 的更新打包机制确实可以把更新分组放在一切来减少消息的数量,但是这仅在相同的 bgp 属性附加到分组前缀时才有效,这个机制并没有被广泛采用.
消息的数量不是导致收敛缓慢的唯一原因,其他原因包括: slow table transfer [13], timers [49, 54] and TCP stack implementation [1]
慢速收敛是域间路由的基本特点,有两个原因.
- 任何路由信息必须以每个前缀为基础进行通告,因为任何一个 AS 都可以针对不通的前缀使用不同的路由策略,使用不同的路径.
- 路由信息不能指示
网络链路的中断routing messages cannot specify network resources that failed,主要是因为路由系统隐藏了 AS 的路由拓扑和路由策略.(多数是因为可拓展性和 AS 级别的隐私要求)
2.1.2 对数据平面连接的影响
为了能够量化 bgp 路由收敛缓慢对数据平面的严重影响,我们使用最新的 cisco 路由器(cisco nexus 7000 c7018 运行 nx-os v6.2) 复制了[图1]的网络,之后我们测量了因为 (5,6) 断链导致的 AS1 路由停机时间.
在连续的实验中,我们配置 AS6 通告的前缀数量不断增长,最多到了 290000(约为当前完整 internet 路由表的一半).我们随机在 AS6 通告的前缀中选择了 100 个 ip 地址最为监控 ip,注入流量,并测量 AS1 检索所有监控 ip 连接性的时间.这种方法为我们提供了探测任何突发状况下任何前缀可能停机时间的下界.
最近的路由器可能需要十几秒才能在远端断路导致的中断中恢复过来.下表显示了 AS1 路由的宕机时间.在链路故障后,路由器开始丢去监控 ip 的数据包.随着从 AS2 收到撤回,和流量重定向到 AS3,连接逐渐恢复.停机时间与前缀数量是线性关系,当前缀数量达到 290k 时,路由器需要 109.0 秒才能完全收敛.
| 前缀数量 | 停机时间(秒) |
|---|---|
| 10k | 3.8 |
| 50k | 19.0 |
| 100k | 37.9 |
| 290k | 109.0 |
2.2 internet bgp 收敛缓慢
现在我们会提供 internet bgp 收敛缓慢的证据,并讨论其对数据层面的影响和网络运营商的观点.
2.2.1 路由撤离非常缓慢 Bursts of withdrawals propagate slowly
我们测量了自 2016 年 11 月从 213 个 RouteViews 和 RIPE RIS 对等会话提取的 bgp 突发撤销的持续时间.
- 我们选择 10 秒的滑动窗口用于提取突发撤销事件.当窗口内 bgp 撤销的数量高于(低于)给定阈值,作为一个突发事件的开始(结束).
- 我们选择 1500 和 9 作为事件开始和停止阈值,分别对应了在 10s 窗口内收到撤销数量的99.99% 和 90%.

最终我们发现了 3335 次突发事件;其中 16% 的突发事件(525)包含了 10000 次以上的撤销,1.5% 的突发事件(49) 包含了 100000 次以上的 bgp 撤销.我们的测量反映了 4 个结果.
bgp 路由经常会出现大量撤回
我们在随机213 个 RouteViews 和 RIPE RIS 对等会话随机选择一个对等会话一直在不断增长的路由器记录观察到的突发事件.图 2(a) 显示了我们观察的结果.
框中的线代表了中值,而框映射了 5% 到 95% 的中位数.只计算中位数的情况下,一个只维持 30 个对等会话的路由器,一个月内至少 104 次超过 5k 次撤回的突发事件.甚至只维持一个会话的路由可能也会收到一些每个月大的突发事件.事实上,62% 的
很多省略
全面了解一次中断非常缓慢.
- 大部分的突发事件在 10s 内就能收到,但 37% (1239) 持续了 10s 以上,9.7% (314) 持续了 30s 以上(入 图2(b)).这意味着突发的路由撤回需要很长时间才能收到.在中位数情况下, bgp 需要 13s 才能收到撤回.
大的断路事件需要 bgp 更长时间学习.
- 总体上 98 次事件超过了 1 分钟,而的撤回数量的平均长度大约为 81k.
撤回的很大一部分发生在突发事件的末尾.
- 我们记录了持续 10s 或以上的突发事件,将每次突发事件分为了时间相等的 3 个部分,头 中 尾,尽管大部分撤销倾向发生在头部时间,但是至少有 50% 的突发有 26%(10%) 撤回发生在中间时间(尾部时间).有 25% 的突发中 32% 的撤回在尾部时间.
84% 的撤销包括了流行 AS 的前缀.
- 我们检查了思科
Umbrella 1 Million数据集,这个数据集列举了前 100 万个最受欢迎的 DNS 域: : Google, Akamai, Amazon, Apple, Microsoft, Facebook,etc. (总共 15 个),84% 的撤销中至少包括了上面提到了一个组织前缀.
- 我们检查了思科
2.2.2 bgp 收敛缓慢会导致大量流量流失
待翻译
2.2.3 72个网络商调查
为了证实路由收敛缓慢对运营的影响,我们对各种网络的网络运营商(ISP cdn ixp 等)进行了匿名调查.这些运营商为庞大的客户团体服务,其中 33% 的用户数量超过了 100万.66% 的用户数量在 1万及 1万以上.
运营商关注到了路由收敛缓慢: 78% 的受防止关心路由收敛缓慢的问题,并通过调整各种参数积极减少本地收敛时间.41 位受访者使用了 BFD(快速检测机制),其中 21 位部署了快速重路由技术或 MPLS.
运营商经常观察到了远程中断导致的路由收敛缓慢,待
绝大多数运营商会考虑 swift,待
swift 概述
![图3][swift workflow]
图3 显示了 swift 的基本工作流,现在我们描述一下发生图1所示情况时,swift 如何运作.
断路前:
- AS1 的 swifted 路由会不断预先计算备份下一跳(与 bgp 路由一致),以便在发生远程中断时使用.这样的预先计算是为了每一个前缀并且会考虑相应 AS 上的任何路径.比如对 AS7 和 AS8 通告的 20k 前缀的路由可以考虑使用 AS3 或 AS4 作为链路 (1,2) 故障时的备份下一跳.相比之下,为了预防链路(5,6)故障,AS1 只能使用 AS3 作为备份下一跳,因为走 AS4 出去也经过 (5,6).
- swifted 会将数据平面的标签嵌入每一个传入的数据包中,每一个 swifted 标签都包括了数据包要通过的一系列 AS 列表,以及在发生任何链接故障时所使用的备份下一跳.
断路发生后:
- 收到链路(5,6) 的故障导致的 bgp 撤销后,AS1 的 swifted 路由器会运行推理算法,快速识别一组可能中断的 AS 链路和可能受影响的前缀.然后,路由会将所有受影响前缀的流量重定向到预先计算的备份下一跳.为了完成重定向操作,swifted 使用了单个转发规则来匹配预先在数据包存在的数据平面标签.
- 作为结果,AS1 在不到 2s 的时间内就重定向了受影响的流量(并且这个过程和受影响的前缀数量没关系).这仅仅是 bgp 收敛所需要时间的一小部分.
- 重路由时,swift 不会在 bgp 中传播任何消息.在 3.3 节我们会证明,swift 的操作是安全的.
- bgp 完全收敛后,即已经接受到了撤回的突发信息,并更新了相应路由表.路由器会删除 swift 的转发规则,回退到 bgp.
下面我们提供了 swift 组件的更多信息.
- 3.1节,我们概述了推理算法(第4节有详细描述),以及 swift 路由如何使用推理的结果.
- 3.2节,我们说明了 swift 如何通过编码算法(第5节详细叙述)预先计算出标签,用于数据层面的快速重路由.
- 3.3节,我们详细证明了 swift 不会在 bgp 中传播任何消息,swift 的操作是安全的.
3.1 从少量 bgp 信息中推理中断
swift 推理算法会在传入的 bgp 消息流中寻找活动峰值.每个检查到的突发事件都会触发对其根本原因的分析.为了分析可能受断路影响最大的链路,这个算法结合了 bgp 消息携带的活动/非活动路径的隐式/显示信息the algorithm combines the implicit and explicit information carried by BGP messages about active and inactive paths.
- 举例来说,图1 中 (5,6) 的断路可能引起 bgp 的撤销,表明由 AS6 和 AS8 发起的所有前缀的 (1,2,5,6) 和 (1,2,5,6,8) 路径不可用.收到这些撤回会使推理算法推理链路 {(1,2),(2,5),(5,6),(6,8)} 断路的概率不断提高.随着时间推移,推理算法会降低链路 (1,2) 和 (2,5) 断路的概率,因为前缀来源于 AS2 和 AS5 的没有受到影响.同时推理算法还会降低链路 (6,8) 断路的概率,因为不是所有的撤回路径都经过 (6,8).
swift 旨在快速推理故障,同时关注准确性.推理的准确性和推理速度是矛盾的,事实上在 bgp 报文很少的情况下精确推理受影响的 AS 链路是不可能.
- 例如,swift 在收到其他 bgp 撤销报文前,无法进一步准确定位链路 (1,2,5,6,8) 断路位置.基于部分路由信息进行的重路由,可能会转移部分本不受断路影响的流量,例如来源于 AS2 和 AS5 的前缀.但是如果不立刻进行重路由,等待 bgp 消息的这段宝贵时间内,向实际受影响链路发送的前缀流量可能会被丢弃.
为了避免不必要的流量重定向,swift 会评估推理结果的现实可能性(例如,使用历史数据的).
- 例如,当推理结果是 AS6 AS7 AS8 发起的前缀全部撤回的突发事件时,swift 会评估突发事件的可能性.如果不太可能发生类似规模的突发事件,swift 会等待更多信息以验证推理结果.鉴于 as7 和 as8 撤回前缀的操作可能和 as6 路径更新的操作交错进行,如同在第 6 节所示,这个策略会使推理快速而准确的收敛到正确的推理.
swift 使用保守的方法将推理转化为受影响的前缀预测.远端中断的影响通常是局部的,即中断可能会使经过该链路的前缀子集的流量丢失.
- 举例而言,图1 中 AS5 和 AS6 之间链路冗余,穿过故障链路(5,6) 的前缀子集可以继续保持正常通行,或者被中间 AS(as5) 重定向到已知备份路径(像是 as7 发起的前缀),由于 bgp 报文信息不足以精确定位所有受影响的前缀集,swift 会将所有穿越推理故障链路的前缀重路由.这样可以最大限度的减少网络中断时间,但是可能会导致路径处于次优化状态(几分钟).
swift 推理在实践中效果很好.我们在真实 bgp 数据上进行推理实验(见第6节)表明,swift 能在收到一小部分路由撤回后,重路由 90% 受影响的前缀,而只影响了 0.60% 的原本不应该重定向的前缀.
3.2 快速的数据平面更新,与受影响的目标数量无关
根据推理,一个 swifted 路由可能需要更新数千个前缀的转发规则.一般而言路由器执行如此大规模的重路由操作会非常慢,因为它们会在每个前缀的基础上更新数据平面规则.根据先前的研究报告每个前缀的更新时间的中位数是 128~282us 之间,因此目前路由器需要 2.7~5.9s 的时间来将 21k 的前缀重路由(图1 中 as1 路由器要做的).即使 bgp 可以瞬间收敛,对于整个互联网(650k 前缀)重路由还是需要 1 分钟以上.
swift 使用数据包的标签进行重路由而不是前缀来加快数据平面的更新速度.swifted 路由器依靠两个阶段来加速数据平面的更新.
- 第一阶段包括标记经过的数据包.swift 标签包含两个信息
- 当前数据包的 AS 转发路径
- 链路正常情况下的下一跳或者 链路故障存在备份路径的情况下 的下一跳.
- 第二阶段包括根据这些标签转发数据包的规则.通过匹配标签的部分内容,swifted 路由器可以快速选择来源于任何 AS 的数据包,并快速将其重定向到预先计算好的下一跳.swift 标签只在 swifted 路由去内部实验,不会在 internet 中传播.(在 swifted 路由出口处,swift 标签会被移除)
还是以图1 的路由为例,我们现在描述 AS1 的 swifted 路由转发表的规则,图3 显示了 swift 编码返回的标签.转发表第一阶段包含了与 bgp 路径一致的添加标签规则The first stage of the forwarding table contains rules to add tags consistently with the used BGP paths.因为 AS8 前缀在路径 (2,5,6,8) 转发,所以会包含如下规则.
1 | match(dst_prefix:in AS8) >> set(tag:00111 10011) |
- 标签中的第一个部分标识了 AS 路径.他将特定比特位子集映射到了 AS 路径中给定位置的 AS 链接.前两位表示 AS 路径中第一条链路,即链路 (2,5),与图 3 一致.第二和第三位表示 AS 路径的第二个链接(5,6)…
标签中的第二个部分(绿色)编码正常和备用下一跳.也就是说第一位标识正常下一跳,第二位是在利链路 (1,2) 失效的情况下要使用的备用下一跳,第三位第四位以此类推.标签的这个部分使得 swift 能够根据故障链路和目的地前缀对可能需要重定向到不同下一跳的流量进行匹配.
在链接 (5,6) 断路之前,第二阶段只包括与 bgp 一致的转发规则.这里具体来说是
1 | match(tag:***** 1****) >> fwd(2) |
在链接 (5,6) 断路后,第二阶段会添加一条高优先级规则,不会修改第一条规则.
1 | match(tag:*01** ***1*) >> fwd(3) |
新增加的规则利用了 swift 的标签结构,一次性重定向了所有受影响前缀为 21k 的流量.
- 上面的正则表达式匹配了所有类似的数据包,即链路 (5,6) 出现在 AS 路径的第二条(即标签以
*01***开始),备份下一跳是 AS3(即标签以***1*结束).这包括了所有以 AS5 AS6 AS8 为前缀的流量. - 请注意在图1 的例子中这一条规则就足够了,因为 swifted 路由不会使用任何在故障前其他位置出现 (5,6) 的 AS 路径.(否则每个位置都需要一条规则)
swift 能有效压缩标签.对于目前超过 220000 个 AS 链路的互联网 AS 图来说,不可能为任何 AS 路径和 AS 路径中所有可能的位置分配比特位.swift 使用了两种方式将这样的图压缩到了很少的比特.
- 目前互联网 AS 图中很多链路很少由路由前缀交叉,它们的故障并不足以导致大的突发事件,甚至根本不需要 swift 对它们进行重定向.因此 swift 根本不需要对这些链路编码.
- 其次,单个路由器在任何给定的时间内使用的 AS 路径数量有限.因此 swift 只对已经在 bgp 路径中存在的 AS 链路和位置进行编码.
swift 支持重路由策略.在计算下一跳时,swift 可以计算符合运营商指定的重路由策略的下一跳.确实在实践中,运营商并不一定总是希望选择理论上安全线路,例如可能因为费用问题等.重路由策略实际是计算下一跳时更倾向于选择某条线路,或者进展使用某条线路即模仿业务和对等协议 mimic business and peering agreements.例如运营商可以阻止 swift
- 使用运营商之间昂贵的链路而不是对客户更方便的链路.
- 选择免费流量接近耗尽的链路
- 将大量流量重定向到地理位置遥远的地区等
swift 支持本地和远程的备份下一跳.除了可以将本地直接连接的路由作为备份下一跳外,swifted 路由器通过使用隧道(IP 或者 MPLS 等)还可以快速重定到远程下一跳(可能在网络的另一侧).远程备份下一跳是通过普通的 ibgp 会话学习的.
swift 部署很容易.部署 swift 只需要软件更新,最新的路由器平台可以轻松的支持两级转发表.在第 7 节中表明通过在 swifted 路由器和其对等路由器之间插入 swift 控制器和 sdn 交换机,swift 也可以部署到任何现有的路由器上.在这样的情况下,两级的转发表跨越了两个设备,类似于 SDX 平台.
3.3 保证与限制 Guarantees and limitations
我们严格证实了 swifted 路由器改善整个互联网连接性与部署的 swifted 路由器数量成正比.这个结论鼓励了在互联网部分或长期部署 swifted 路由器(例如,在所有 AS 边界路由器部署).
定理:
- 定理 3.1: 每一个处于受故障影响路径上的 swifted 路由器都会减少出现中断路径的数量.
- 定理 3.2: 无论如何配置 swifted 路由器,swift 重路由都不会引起环路.
这两个定理都是基于以下引理.
- 引理3.3: 当 swifted 路由器进行快速重路由时,始终都会在没有黑洞和环路的路径上发送数据包.
证明草图
在发生远程中断时:
- 任何 swifted 路由器 r 会将流量重路由到中断发生前 ,bgp 邻居之一提供给 r 的 AS 路径上(根据 swift 定义).
- 这个路径是没有黑洞和环路的(根据 BGP 定义).
- 另外这条路径不包含故障链路(前提是推理足够准确).
因此这条链路依旧有效,并且被其中的 AS 使用,这直接产生了引理3.3.
从证明草图上可以看出,在下面两个假设成立的条件下,上面提到的引理和定理都是成立的.
假设1: 在中断发生后,路由器只改变受影响的域间转发链路.如果违反了这个假设就会产生域间环路.假设 s 是一个 swifted 路由,n 是 s 为了避免某次中断而选择的下一跳.如果 n 是某些快速路由前缀切换的路径(例如,反应与故障无关的策略变化),它可能会选择故障前 s 使用的 bgp 路径(不是 swift 更新的):这可能会导致 n 与 s 的环路.不过 swift 可以快速检测和缓解这样的环路,s 可以监控 n 是否停止给它的快速重路由提供 bgp 路径,并且 s 可以选择另一个备份下一跳.
假设2: swift 推理会使 swifted 路由器避免受到中断链路的影响.swift 推理算法实现了非常保守的推理链路和选择备份路径.但是我们没有办法保证这个假设的有效性,
因为 swift 推理是基于 bgp 提供的部分信息和噪声信息since SWIFT inferences are based on the partial and potentially noisy information provided by BGP(以及在不同时间达到的 AS 撤销信息).如果 swift 的推理没有排除素有受影响的链路,可能会诱发数据包丢失.- 一个 swifted 路由器可能将流量重路由到一个已经断路的备份
- 多个 swifted 路由器可能形成环路(如果所选的备份下一跳实际上正好是被推理遗漏的中断路径之一)
在这两种情况下,数据包都会被丢弃,就像没有使用 swift 的情况下,受影响的前缀链路中断.然而在使用实际 bgp 数据和受控条件下进行的模拟评估表明,swift 很少会因为推理导致选择已经中断的链路作为下一跳.
4 swift 推理算法
这一节中详细介绍了 swift 推理算法
- 4.1 节是算法基础
- 4.2 节是算法需要考虑的现实因素
因为篇幅所限,算法的伪代码和正确性证明在[1].
4.1 快速而合理的推理
在下文中,我们考虑做如下假设
- 假设在单个 bgp 会话收到的消息流,因为该算法是在单个会话的基础上运行的(实现了并行).
- 假设算法的目的是推理出由一条链路故障导致的中断.
突发检测
- swift 会监测收到的 bgp 报文流,寻找撤回频率显著增加的情况.
- 当输入流的撤回频率(例如 10s 内撤回的数量)高于最近历史记录(例如上个月历史数据)中 99.99% 的时间时,算法会将这组消息作为一个突发事件的开始.
故障定位
- 当监测到突发时,swift 会将一个叫作 Fit Score (FS) 的值最大化的链路推理为故障链路.以 t 作为完成推理的事件的时间,任何一个链路 l,对 l 而言其 FS 值为 Withdrawal Share (WS) 和 Path Share (PS) 的加权几何平均值.
WS 指的是在 t 时间,路径包括链路 l 的被撤销前缀 占 所有被撤销前缀的比例.
PS 是 t 时刻,路径包括链路 l 的被撤销前缀 占 变化路径包括 l 的前缀的比例.(
变化是指撤销和新生成的路径)具体而言路径包括 l 且在 t 时刻被撤回前缀的数量.
是截至 t 时刻,收到的被撤回的总数量.
是截至 t 时刻,变化后的新路径仍然包括路径 l 的前缀数量.
和 是我们分配给 WS 和 PS 的权重.
对 WS 和 PS 进行拟合得到一个数值的目的是量化一条链路收到撤回的相对概率,这个数值对现实因素(例如 4.2 节将要提到的 BGP 噪声)具有鲁棒性.

图 4 显示了如图 1 中链路 (5,6) 断开后,WS 和 PS 值.
- 链路(5,6) 是唯一 WS 和 PS 都等于 1 的链路,因为所有经过它的 AS 路径都被撤回或改变了,没有路径穿过链路(5,6).
- 链路(1,2) 和 链路(2,5) 则相反. PS 值小于 1(11k/13k 和 11k/12k).因为 AS2 和 AS5 的前缀没有被突发事件影响到.
- 链路(6,8) 的 WS 小于 1,因为不是所有撤回都与该链路有关.
- 最后链路(5,6) 被正确推理为故障链路.
swift 的推理是合理的.准确来说,我们的意思是在理想条件下推理算法总是正确的,因此下面的定理成立.
定理 4.1: 如果所有 AS 在每条链路至少注入一个前缀,在相应 bgp 报文流结束时,swift 会返回包括故障链路在内的一组链路.
简略证明: 设 f 为故障链路,t 为 f 故障引发的所有 bgp 报文被接收的时间.所有被撤回的前缀之前都是经过链路 f 中转,因此 ,同时,之前所有在 f 上中转的前缀都被撤销了,,拟合后 f 有着最大故障可能性 (FS),swift 推理算法可以将它放在返回的一组可能故障链路中.
4.2 对现实世界的鲁棒性 Robustness to real-world factors
尽管在现实中 bgp 消息流并不总是如定理 4.1 那样理想条件相同,但是 swift 推理在实践中依旧是最好的(参见第6节),接下来我们解释原因.
swift 可以在突发事件期间就做出准确判断.与定理 4.1 的假设相反,swift 推理算法在突发事件开始之后就已经开始运行了,因此信息的缺乏(即尚未收到的 bgp 撤销)会影响推理的准确性.swift 也意识到了信息的缺乏,因此对 FS 计算中对 WS 和 PS 使用了不同的权重(见 4.1 节).
- 一个关键的地方是,在突发事件早期,大量前缀还没有被撤销,依旧在使用断路的链路,结果就是断路链路的 PS 值可能不是最高的.当突发事件发生,swift 开始推理过程,故障链路的 PS 实际上会升高.
- 但是故障链路的 WS 值将始终大约等于其他所有链路的 WS 值,前提是 swift 没有收到无关的 bgp 撤销.因此在结论中, > 时,swift 的表现会更好.
- 在实际的 bgp 数据测试中,我们发现当 比 大 3 倍时,swift 性能最好(参见 [33]).因此我们将此权重应用于 swift,第六节的评估也使用此权重.
swift 通过自适应,将推理错误的风险降到最低.如第三节讨论的那样,swift 推理的准确性取决于输入的信息量.
swift 使用正在进行的突发事件的撤回总数作为信息进行推理.它会在固定的撤回总数(称之为触发阈值)后启动第一次推理.如果通过历史数据得出发生突发情况的可能性很高,那它就会返回推理的故障链路.否则它会等待撤回达到一个固定的数量再返回推理的结果.
使用真实的 bgp 数据作为基线,我们将触发阈值设置为了 2.5k 撤回.另外
- 对于小于 2.5k 的撤回,如果预测收到的前缀总数小于 10k,swift 会立刻返回推理结果
- 预测 20k 前缀,撤销 5k ,预测 50k 撤销 7.5k,预测 100k 撤回 10k,都会立刻返回推理结果.
- 如果超过 20k 撤回,无论预测的前缀总数如何,都会立刻返回推理结果.
如果无法快速确定故障链路,swift 将使用保守的策略.
- swift 可能无法快速区分那个链路出现故障,例如图4,swift 无法区分链路(5,6) 和 链路(6,8) 具体哪一个发生了故障.
- 每当无法明确具体故障链路时,swift 会返回所有具有最大 FS 的链路.这个例子中 swift 会返回 链路(5,6) 和 链路(6,8).
swift 的量化指标减少了 bgp 噪音的影响.
一些收到的 bgp 消息可能和突发的中断没有关系,这些信息可能由偶然因素引起(如配置错误,路由器错误等).这些信息构成了 bgp 噪音,会影响推理的准确性.
在 swift 中,bgp 噪音可能会扭曲 FS 的值,以图 4 为例,在链路 (5,6) 故障开始后,AS5 发起的前缀撤回可能被 AS1 接收,可能使得 链路(2,5) 的 FS 值大于 链路(5,6),特别是在故障发生的最初阶段.
事实上,swift 对实际的 bgp 噪声具有鲁棒性.因为 bgp 噪声的影响通常要远远小于链路故障引起的突发事件.因此 bgp 对定量指标(WS PS FS)的影响会迅速下降.这样的特点使得 swift 推理算法有别于其他类似算法,例如基于 AS-path 交集的算法,其对单个不相关撤回更敏感.
swift 可以推理出同时发生的链路故障.
- 为了覆盖路由器故障同时会影响多个链路的情况,推理算法可以计算共享一个端点的一组链路集合的 FS 值.具体来说是,
算法可以将具有共同端点的链路贪婪的聚合起来(按 FS 最高值到 FS 最低值),直到所有聚合链路的 FS 值不再增加the algorithm aggregates greedily links with a common endpoint (from links with the highest FS to those with the lowest one), until the FS for all the aggregated links does not increase anymore.通过拓展 WS 和 PS 的定义,可以对任意一组链路 S 的拟合计算 FS 值,如下所示
- 返回具有最高 FS 的链路集合(可能只有单条链路),为了确保安全(见 3.3 节)对于每个推理的链路,swift 必须选择一个不穿过公共顶点的备份路由.这可以防止 swift 将前缀重路由到另一个也推理为故障链路的备份下一跳(因为这一组链路有共同的端点).通过选择绕过推理故障链路的超集,在推理算法仅正确定位故障中涉及 AS 而不是某条精确链路的情况下,swift 还可以确保安全.
5 swift 编码算法
本节我们将介绍 swift 标签是如何计算的.回想一下,这些标签会在转发表第一个阶段前,嵌入到传入的数据包上,分为两个部分:第一部分编码数据包正常情况下使用的 AS 链路,另一部分编码数据包在正常链路任何一个链路故障时需要重路由的备份下一跳.因为标签的存在,swift 的重路由操作非常高效,不受被影响的前缀数量多少影响.
在第 7 节,与 [30,31]类似,我们将展示 swift 如何利用目的地 mac 写入标签标记入站流量.目的地 mac 确实是一个非常好的标签载体,它提供了非常长的位数(48),并且非常容易在转发的第二阶段可以再将其改写为实际的目的地 mac 来删除标签.
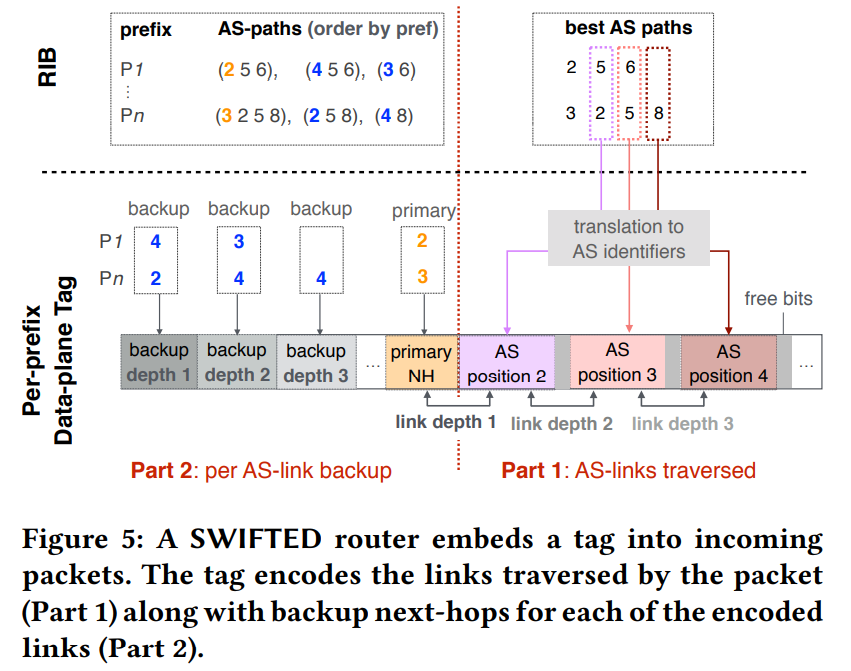
编码 AS 链路.标签的第一个部分(如图 5 所示) 编码了数据包流经的每一个 AS 路径.
- 对每一个前缀,我们考虑它在最佳路径情况下的 AS 路径,并存储该路径中的 每个 AS 的位置.即我们定义了一个 m 的 set,m 是 AS 路径最长的长度,我们称 set 中第 i 个位置元素为 .对于任何一个 AS 路径 ,,对于所有的 ,我们将 的 AS 标识符添加到 m 的第 i 个位置.
- 请注意,任何 AS 路径的第一跳都被标记为了主要下一跳(图5 的第二部分),因此我们不对位置 1 编码.
我们对每一个 swift 的邻居都有不同的 AS-path 编码and we have a different AS-path encoding for every SWIFT’s neighbor.这个过程结束后,就可以在每个位置填入特定的 AS 标识符来编码整个 AS 路径.
不可能全部的 AS 路径进行编码,不仅仅是因为可能有上千个不同的 AS,AS 路径也可能非常长(> 10跳).幸运的是,有两项观察结果可以使 swift 大大减少编码所需的位数.
- 首先从路由器的角度看,许多 AS 链路只携带少量前缀.这些链路的断路只会产生较小的突发事件(如果有的话),
在这样的情况下按前缀更新路由问题不大which allows for per-prefix update. 因此,在进行 swift 编码时,我们将忽略任何少于 1500 前缀的链路. - 其次,距离 swifed 路由较远的链路比距离较近的链路更不可能产生突发中断.实际上,对于远距离链路,中间节点很可能知道备份路径,我们的测量(第 6 节)证实了这一点.因此我们仅需要编码 AS 路径的前几条(直到第 5 跳).
对于其他的 AS 链路,swift 首先对中转最多前缀的链路进行编码.为此 swift 对每个 AS 位置使用了自适应位数:每个位置使用不同的位数,这个长度取决于这个位置 AS 的数量.对每个位置 P,我们将与 P 关联的所有 AS 映射到相应位组的一个特定值(AS 标识符),这个位组的大小等于位置 P 所有值所需要的位数.
编码备份下一跳.标签的第二部分(图 5 左侧)标识了每个编码 AS 链路的主下一跳和后备下一跳.对于每个前缀 p,直接提取主下一跳作为 p 在 AS 路径中的第一跳.
- 例如,图 1(a) 中前缀 p1 的主下一跳是 2.
备份下一跳被明确标识出来了,以反映重路由策略并防止重路由到中断的备份路径.
- 再次考虑 p1,主要路径是 (2,5,6),为了防止链路 (2,5) 故障,可以选择 AS3 和 AS4 作为备份下一跳,因为两者都可以不使用链路 (2,5) 到达 p1.
- 相反对于链路 (5,6),由于走 AS4 的备份路径也要走 链路(5,6),因此只能选择 AS3 作为备用下一跳.
需要对标记的两个部分进行分区.在路径数量和任何 swifted 路由器可以编码的备份下一跳数量之间取得平衡.
- 一方面,分配更多的比特表示 AS 链接(标记的第一部分),可以让 swifted 路由器覆盖更多的远程故障.
- 另一方面,分配更多的比特表示备份下一跳(标签第二部分),swifted 路由器可以将流量重路由到更多备份路径.
在 6.4 节中,我们表明了分配 18 位给 AS 路径编码,足够编码重路由 98% 以上的前缀.假设标签一共有 48 位(即使用目的地 mac),剩下的 30 位用于编码下一跳.
- 假如我们将 swifted 路由器配置为支持深度为 4 的远程故障处理,那么分配给备份下一跳的位数需要除以 5(1 主+4 备份),因此为每个深度保留 30/5 = 6 比特,即 种下一跳可能.
- 如果只考虑深度为 3 以内的远程故障,那么下一跳的数量可以是 种可能,可以分配 2 个比特位表示 AS 路径.运营商可以根据每个 swifted 路由器可达的备份下一跳数,对深度进行调整.
6 评价
现在我们对基于 python 的 swift 推理算法(第4节)和编码方案(第 5 节)的实现(约 3000 行代码)进行评估.
- 6.1节,描述了测试用的数据集
- 6.2节,从故障定位的角度评估了推理算法
- 6.3节,从撤回预测的角度评估了推理算法
- 6.4节,评估了 swift 数据平面的编码效率
- 6.5节,证明了 swift 的推理算法与编码方案结合可以实现比 bgp 更快的收敛.
6.1 数据集
我们使用两种 bgp 撤回的两种突发来源来评估 swift.
真实 bgp 数据.没有记录突发事件(准确来说是不能记录下来)
- 为了评估 swift 在真实世界中如何工作,我们使用了与第 2 节相同的数据集提取实际的突发事件.整个数据集是由 2016 年 11 月整月的 10 个 routeview 和 5 个 rire ris 收集器转储的 bgp 消息组成,这些收集器是从 213 个对等方收集 bgp 消息.
- 我们的评估基于 1802 次突发事件(每次都超过 1500 次撤回).其中 942 次超过了 2500 次撤回.339 次超过了 15000 次撤回.
来自模拟的突发事件.有准确记录突发事件
- 为了验证推理算法的准确性和鲁棒性,我们使用了 C-BGP 进行控制层面模拟,提取突发事件.
- 我们使用 Hyperbolic Graph Generator 生成了一个 1000 个 AS 组成的拓扑结构,平均节点度设置成了与上文实际 bgp 数据集相同的 8.4.
使用 2.1 作为度分布and use as degree distribution a power law with exponent 2.1 [42]. - 我们定义如下的 AS 关系:
- 度数最高的 3 个 AS 是 Tier1 ASes 并且是 fully-meshed.
- 与 Tier1 直接相连的是 AS 是 Tier2,与 Tier2 直接相连但不与 Tire1 相连的是 Tire3…以此类推.
- 我们给每个 AS 配置 20 个前缀,共 20k 前缀.
- 使用 C-BGP 模拟随机链路故障,并记录网络中每个 BGP 会话收到的 BGP 消息
- 我们总共记录了 2183次 超过 1k 的突发撤销,撤销的中位数(最大数) 是 2184(19215).
6.2 故障定位精度
接下来我们评估 swift 在两个数据集的准确性.
6.2.1 验证实际 bgp 数据
因为真实的 bgp 追踪数据,没有记录突发事件的根本问题.因此我们间接的估计推理算法的准确性.
我们评估整个突发中被撤销的前缀 与被包含 swift 推理为故障链路的前缀 之间的匹配度.we evaluate the match between the prefixes withdrawn in the entire burst W and the prefixes W′ whose path traversed the links inferred by SWIFT as failed.- 这样可以将其形式化为二进制分类问题,其中 true 是 false 是 的前缀,因此我们使用 TPR(真阳性) 和 FPR(假阳性) 来评估推理算法.

图 6 显示了,每次突发的 TPR 和 FPR.图分成了几个象限.
- 左上角象限对应非常好的推理,即对应于每个突发 swift 推理为故障的链路被大多数撤销的前缀(高 TPR)和少数未受影响的前缀(低 FPR)包含.
- 右上角象限包括了高估故障程度(高 TPR 高 RPR): 由于 TRP 很高,这样的推理依然是有益的(即实际许多被破坏的前缀得以恢复连接性).
- 左下角是低估了故障程度
- 右下角是完全判断错误(低 TPR 高 FPR)
我们评估了 SWIFT 的两种场景
- 第一个场景(图 6.a),推理算法在收到 2.5k 撤回后运行一次并返回结果,没有历史数据.(就行路由器第一次安装 swift)
- 第二个场景(图 6.b),推理算法在收到 2.5k 撤回后开始运行,同时如 4.2 节那样,返回时考虑历史数据.考虑历史数据后,swift 在更多的撤回达到后,才会在突发早期重定向大量前缀.
在绝大多数情况下,swift 都能做出准确的推断,而且从未做过错误推断.
- 即使在只使用 2.5k 撤回的情况下,swift在绝大多数情况下也能正确推断,如 图6.a 所示.
在大部分情况下, 81% 以上的突发事件的 TPR 高于 60%.但是它也高估了 12% 突发事件的故障程度(FPR 高于 50%): TPR is more than 60% for more than 81% of the bursts. However, it also overestimates the extent of the burst (FPR is higher than 50%) for about 12% of the bursts. - 依靠历史记录时,效果明显更好.如图 6.b 所示.但这样会牺牲一些速度,总的来说与无历史数据相比,总共错过了 256 次突发事件,尽管对于大多数突发事件 (65%) 基于历史的推理算法仍然以最低阈值 (2.5k) 完成了推理.图 6.b 左上象限的密度清晰表明了牺牲一点速度换取精度的收益.
- 最后我们强调,无论是否使用历史数据,swift 都没有落入右下象限(错误推理)
6.2.2 仿真验证
我们现在描述在 c-bgp(见 6.1 节) 生成突发事件时,swift 推理算法运行的结果.
在理想条件下,swift 推理始终是正确的.我们在每次突发事件结束时运行推理算法,发现推理总是正确的,与定理 4.1 一致.
swift 推理足够准确以确保安全,甚至在突发事件发生期间也是如此.
- 我们在仅 200 次撤回后就运行了推理算法,swift 识别了 9% 的突发故障链路的超集,剩下的 91% 则返回了一组与失败链路相邻的链接.
- 但是对于 2183 个突发事件中,除了 2 次,swift 都能找到一条实际绕过故障链路的备用路径.这是因为 swift 选择备用路径时不会选择经过推理故障链路的公共端点(4.2节).
swift 推理算法对噪声具有鲁棒性.
- 我们模拟在 bgp 中加入噪音,在每个突发事件中添加不受故障影响的 1000 个前缀撤回.这个数值要比我们在实际 bgp 数据中观察到的要大得多.无论是在绝对数量上看(90% 的撤回中仅有 9 个撤回),百分比来看(我们在 C-BGP 中只有 20k 前缀,而真实世界超过了 600k 前缀)
- 我们在突发结束后,返回推理结果时.swift 对 91% 的突发事件(1991) 识别了故障链路,对 9% 的突发事件(188) 识别了包含故障链路的超集,对 1 个突发事件识别了与故障链路相邻的一组链路,对 3 个突发事件,做出了错误推理.
- 当我们在 200 次撤回后就返回推理时,swift 依然为所有突发事件选择了绕过实际故障链路的备份路径,只有 1 个失败.swift 为 12% 的突发事件识别了包含故障链路的超集,另外 88% 的突发事件,swift 返回了一组与故障链路相邻的链路.
6.3 撤回预测的准确性
在 6.2 节我们的测试显示了 swift 推理算法即使在信息有限的情况下,也能正确识别故障链路.
在本节中,我们评估了 swift 预测撤回的能力,并且我们还给出了推理后快速改道的前缀数量,这使我们能够量化 swift 的好处以及可能的问题.
与上一节不同,为了具体的评估预测结果的准确性,我们只将推理后撤回的前缀认为是 “正数” we consider as “positives” only the prefixes withdrawn after the inference was made.这个变化影响了 TP(TPR) 的定义,但没有影响 TP(FPR).我们在 6.2 节已经使用了 TPR 所以我们使用 CPR (代表正确预测率) 表示预测的真实比例,同时我们也使用 CP 和 FP 表示正确预测和不正确预测的前缀数.
6.3.1 验证实际 bgp 数据

表2 显示了是运行带历史数据 swift 推理算法的结果,分别使用了 小(<15k) 的突发事件和 大(>15k) 的突发事件测试.
swift 能够快速重路由大量受影响的前缀.
- 对于一半(或 80%) 的小规模撤回,swift 至少正确预测 89.5%(或 48.9%)的未来可能撤回前缀.
- 对于一半(或 80%) 的大规模撤回,swift 至少正确预测了 93%(或 39.3%)的未来可能撤回前缀.
从绝对数字来看,swift 快速重路由了大量前缀.特别是对于较大突发事件(> 15k),其中 60% 突发事件的预测前缀数量是数万,10% 以上的突发事件预测前缀数量是数十万.
swift 仅仅重路由了少量本不受影响的前缀.
- 无论是大的还是小的突发事件,绝大部分情况下,未受故障影响的路由就被重定向的路由只占被重定向路由的一小部分.
- 然而,在少部分情况下(例如
大的突发事件 90% 中位数90-th percentile of the large bursts)swift 算法要显著高估了需要重定向的前缀数量(FP),这是因为我们刻意设计调整了算法,以避免遗漏应该重定向的前缀. - 不需要重定向前缀被重定向了,确实会使流量进入一个次优的备份路径,但是流量并没有中断,而且仅仅会发生在 bgp 重新收敛的几分钟内.
- 当然我们注意到了,权重不那么激进确实会降低 FPR.
6.3.2 仿真验证
这一节,我们通过 C-BGP 生成的随机突发来评估前缀预测的准确性.
即使考虑到 bgp 噪音,swift 仍然可以准确预测前缀的撤回.在仅收到 200 次撤回就返回推理结果时.
- 98% 的突发事件的 FPR = 0.
- 观察到的最高 FPR 只有 13%.
- 在中位数情况下(25%),CPR 等于 88%(84%),最低的 CPR 是 37%.
为了考虑到 bgp 噪声的影响,我们在每个突发中增加了与故障无关的 1000 次撤回(同 6.2.2 节)
- 53% 的突发,FPR 仍然为 0.仅 1% 的突发 FPR 大于 9%.
- 在中位数情况下(25%),CPR 为 53%(50%).
CPR 远非 100%,因为与故障无关的撤回被视为阳性.在实践中,我们观察到 CPR 受 BGP 噪声影响较小,因为通常情况下噪声水平要小的多(参见 2.2 节).
6.4 编码效果
我们现在要通过实验评估 swift 编码方案(见第 5 节),量化在数据平面上预先匹配提供的标签可以有效的重定向多少前缀.
对于每个突发事件,我们将编码性能定于为编码方案可以重定向的预测前缀的分数.性能取决于分配给标签 AS 路径的比特数(见第 5 节).
在评估部分,我们使用带历史模型的推理算法,并使用从真实 bgp 数据提取的数据集进行测试.

标签的前 18 位分配给标签的 AS 路径部分,可以重路由预测前缀的 98.7%.
图7显示了编码新方案的性能(在所有突发事件中)与为 AS 路径保留多少比特位的关系.
每个方框显示编码性能的 4 个分数的范围
- 框中直线表示中值.
- 点表示了平均值
- ~~虚线表示了 5% ~ 95%.~~the whiskers show the 5th and 95th percentiles.
随着给 AS 路径编码的比特位增加,编码的性能也会提高.我们可以看到,在取中值的情况下,18 位已经足够重路由 98.7% 预测前缀了(平均 73.9%).
以上结果表明,编码算法的压缩是有效的,并能对绝大多数相关 AS 链路进行编码.
此外 图7 显示对于至少 10k 的大突发事件,编码性能更好(18 位时平均为 84%)
- 这是编码算法设计导致的,编码算法会优先编码有最大数量前缀遍历的 AS 链路(链路故障时,会造成更大影响).
假设标签是 48 位,那么剩下 30 位可以用于编码备份下一跳.如果 swift 选择编码到深度 4 (即 AS 路径中的位置 5),那标签的第二部分,每条路径可以使用 64 个备份下一跳.
这表明,swifted 设备即使连接到了大量邻居,例如 IXPs 等,swift 编码也能很好的工作.甚至可以减少编码的 AS 跳数来增加备份下一跳数量(例如: 深度是 3 而不是 4)
6.5 重路由速度
在这一节,我们量化了 swift 推理算法和编码方案,表明了在实践中,这个方案能快速收敛(2s 内)
- 预测所需要时间
- 数据平面执行规则的更新次数.
我们是根据实际 bgp 数据中的突发事件来进行测试的.

swift 学到了足够信息的情况下,可以在 2s 内收敛,(中间值).与 BGP 相比 swift 收敛速度比工作在前缀级别的 bgp 快得多.
图8 显示了从从突发开始,到学习到突发的每次撤回,之间实际时间的 CDFFig. 8 shows the CDF of the time elapsed between the beginning of the burst and the actual time at which every withdrawal in the burst is learned.
- 对于 bgp ,学习时间对应撤回的时间戳
- 对于 swift,如果是预测撤回,则对应预测时间,否则对应时间戳.
图中的显示
- 在中位数条件下,swift 在 2s 内就完成了学习撤回,而 bgp 需要 13s
- swift 曲线在 41s 时,有一处转变.调查后发现,那是因为有一个非常大的 510k 前缀撤回时间,总共花了 105s 才达到.
- 第一个 20k 撤回的时间需要 40s 才能到达,但即使在这样的情况下,swift 还是减少了 1 分钟以上的潜在停机时间.
swift 几乎不需要数据平面更新即可重路由所有预测前缀.重路由 所有预测可能受影响前缀而需要的数据层面更新条码的数量 取决于推理算法报告的失败链路数量.
在收到 2.5k 撤回后,运行推理算法时,在 29% 的情况下,推理返回的故障链路是 1 条,中位数(90%)是 4(29).
对每个被推理失败的链路,每个备份下一跳都需要一个数据平面的更新.因此在中位数 (90%) 的情况下,有 16 个备份下一跳的情况下,需要 64(464) 个数据平面更新.
考虑到每个前缀的更新时间中位数在 128~282us 之间.swift 可以在 130ms 内更新所有转发条目.
7 案例分析
本文中我们提到了通过在 cisco 最新的路由器的收敛时间来展示 swift 的优势,正如 3.2 节提到的,部署 swift 只需要简单的软件更新即可直接在现在的路由器上实现,唯一的硬件要求是两级转发表,这是最新平台都支持的(我们与一家主流产品供应商确认过).然而为了评估 swift 而不是等待厂商来实现,我们开发了一个替代的部署方案.
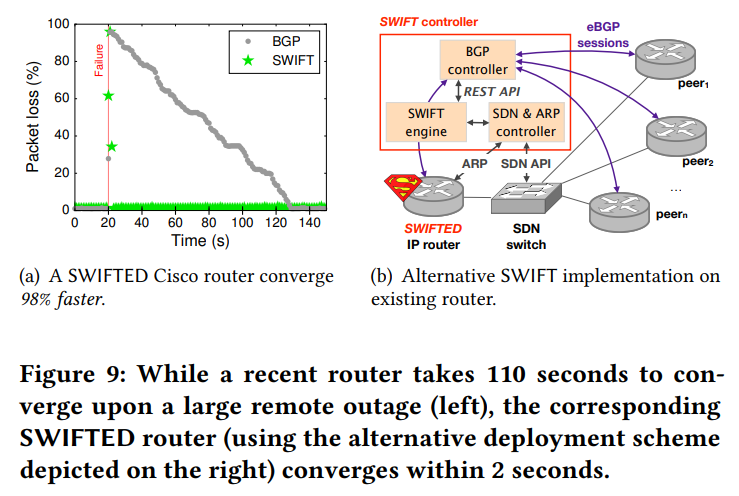
如何使现有的路由器支持 swiift? 在我们的替代部署方案中,我们在 swifted 路由器和其对等设备之间,分别在控制层和数据层插入了一个 swift 控制器和一个 sdn 交换机(如图 9.b).这样的设置类似 sdx 平台.它可以使任何支持 bgp 和 arp 的路由器部署 swift,这几乎使得所有路由器都可以部署 swift.
当接收到对等体的 bgp 更新后,swift 就会在路由器上开始部署.
- 控制器根据 swift 的编码方案分配 48 位标签(见第 5 节).
- 控制器对 swifted 路由器进行编程,使用与 SDX 相同的技术(即使用 bgp 和 arp).将数据平面标签嵌入传入的数据包包头的目的地 mac.
- 控制器还对 sdn 交换机进行编程,根据标签对流量进行路由并且将目的地 mac 改写为实际下一跳地址.
- 然后,swift 使用 的两级转发表跨越了两个设备: swifted 路由器和 sdn 交换机.
- 当检查到对等体的突发事件时,swifted 会运行推理算法(第 4 节),并向 sdn 交换机提供数据平面规则,以便对流量进行重定向.我们使用 exabgp 维护 bgp 会话.
方法:
- 我们使用一台最新的路由器(cisco nexus 7k c7018,运行 nx-os v6.2) 作为 AS1 重现了如图 1.a 的拓扑结构.
- 通过 一台运行(基于软件) openflow 的交换机(openvswitch 2.1.3) 的笔记本电脑将其连接到对等设备.
- 将 AS6 配置宣布为 29 万前缀,然后中断链路(5,6).使用与第 2 节相同的技术(向 100 个随机选择的 ip 地址发送流量)测量停机时间.
如 图9.a 所示,swifted 路由器和 非swifted 路由器的停机时间.vanilla cisco 需要 109s 才能收敛,而 swifted cisco 路由器只需要 2s 收敛,提高了 98%.
8 相关工作
9 结论
我们叙述了 swift,第一个专门用于远程故障快速重路由的框架.
swift 有两个主要共享
- 快速准确的推理算法
- 新颖的编码方案
我们通过使用实际的 bgp 数据和模拟数据,对 swift 进行了全面评估.结果表明,swifted 在实践中是有效的,他的预测精度与编码效率均超过了 90%,并且可以和 cisco 路由器结合使得收敛性能提高最多 98%.
10 图片
Thomas Holterbach, Stefano Vissicchio, Alberto Dainotti, and Laurent Vanbever. 2017. SWIFT: Predictive Fast Reroute. Tech. Report (2017).
https://swift.ethz.ch↩︎